
В прошлой статье мы разобрались с тем, что такое искусственный интеллект, как устроены нейросети и чем они похожи на человеческий мозг. Я обещал продемонстрировать работу нейронных сетей на каком-то простом примере. И распознавание рукописного текста, как мне кажется, прекрасно подходит для этой задачи.
Но тут вот какое дело. Deep-Review — это, прежде всего, про мобильные технологии. А на рынке сегодня есть лишь один мобильный телефон с поддержкой пера и рукописного ввода. Конечно, я имею ввиду линейку Galaxy Note с пером S-Pen от компании Samsung.
Логично предположить, что для распознавания текста нужен, как минимум, сам текст. Но знаете ли вы, как он появляется на экране смартфона? Почему перо S-Pen не работает с другими телефонами? Каким образом Galaxy Note реагирует на приближение S-Pen к экрану, если пользователь даже не прикасается к нему? Как на S-Pen работает кнопка, если там нет никаких батареек?
Уверен, если вы пользовались или пользуетесь смартфоном Galaxy Note (или планшетом с поддержкой пера), вас интересовали похожие вопросы. Поэтому вначале я бы вкратце хотел объяснить эту технологию, а затем приступить к теме распознавания текста с помощью искусственного интеллекта (точнее, машинного обучения и нейросетей).
Как работает перо S-Pen на Galaxy Note?
Начнем с фокусов! Для этого попрошу пользователей Galaxy Note подойти поближе. Итак, включаем экран смартфона, достаем перо S-Pen и создаем новую заметку.
А теперь делаем то, чего раньше вы, скорее всего, никогда не делали. На экран смартфона кладем журнал/книгу и обводим пером S-Pen любую картинку, едва касаясь ее (можно между бумагой и экраном положить любой слой изоляции, вроде пластика или резинового коврика):

Убираем книгу и… как это возможно!? На экране смартфона появилось все то, что мы обводили пером:

Теперь повторяем фокус, но уже без книги. На расстоянии в пару сантиметров от экрана прикасаемся пальцем к кончику пера и дальше продолжаем рисовать по воздуху. Чем сильнее палец прижимает наконечник пера, тем толще линия на экране. То есть, дисплей чувствует несуществующую силу нажатия!
Этот простой эксперимент доказывает, что ни наконечник пера, ни сам экран не имеют никакого отношения к работе S-Pen. Соответственно, внутри Galaxy Note есть что-то еще, что принимает по воздуху сигнал от S-Pen.
Стоп! Получается, перо не рисует по экрану (как мы делаем это пальцем), а отправляет какой-то радиосигнал в смартфон? Именно!
Перо S-Pen — это не просто кусок пластика в виде ручки, а специальное радиоэлектронное устройство, для работы которого нужно питание.
Внутри S-Pen есть антенна, чип и передатчик. Сила нажатия «на экран» — это в реальности сила нажатия на наконечник пера. Перо вообще никак не взаимодействует с экраном, поэтому S-Pen и не работает с другими смартфонами. Этой ручке нужен не сенсорный экран, а другая деталь, спрятанная глубоко внутри Galaxy Note. Но обо всем по порядку.
Для начала посмотрите, как выглядит S-Pen в сломанном разобранном виде:

Мы видим антенну и плату, но где батарейка? Начиная с Galaxy Note 9, внутри S-Pen есть крохотный элемент питания для поддержки Bluetooth-функций (подробнее об этом читайте в обзоре S-Pen), но он не имеет никакого отношения к основной задаче — работе S-Pen в качестве пера.
Откуда же ручка берет энергию? Она передается по воздуху от смартфона!
Под экраном Galaxy Note (за стеклом, сенсорным слоем и матрицей) спрятана антенна. Верне, целая сетка из антенн. Когда электричество проходит по ней, возникает магнитное поле. То есть, антенна начинает излучать электромагнитные волны в точности, как «ядовитые» вышки 5G, правда, на совершенно другой частоте. Но так как мощность этого радио-излучения очень мала, поймать такой «радиосигнал» можно только в непосредственной близости к экрану (~2 см).
Наш мир устроен так, что электрическое поле порождает магнитное, а магнитное поле — электрическое. Грубо говоря, если вы будете водить магнитом туда-сюда над простой проволокой, внутри нее возникнет ток. Правда, вы его не почувствуете, так как ток, создаваемый таким движением магнита, будет слишком мал. И наоборот, если пустить ток по проволоке, вокруг нее образуется магнитное поле.
Чтобы увеличить силу тока, проволоку наматывают в виде катушки (чтобы было как можно больше проволоки сконцентрированной в одном месте) и когда такая катушка внутри S-Pen попадает в область магнитного поля экрана (антенны под экраном), она начинает индуцировать ток:

Принцип работы S-Pen следующий:
- Антенна внутри смартфона излучает радиоволны сквозь экран. Это очень слабое излучение, поэтому поймать его на большом расстоянии не получится.
- Как только вы подносите S-Pen близко к экрану, его антенна оказывается под действием магнитного поля и по проводу антенны начинает проходить ток.
- Электричество питает микросхему пера. Теперь и само перо начинает передавать сигнал. Когда вы нажимаете кнопку или прижимаете наконечник пера (к экрану смартфона или любому другому предмету), частота сигнала слегка изменяется (то есть, сигнал модулируется).
- S-Pen отправляет ответный измененный сигнал и антенна смартфона принимает его. Затем контроллер (специальный чип) внутри смартфона определяет координаты пера, основываясь на том, возле каких антенн был самый сильный уровень приема.
Вот и весь секрет!
Но теперь мы подходим к другому вопросу, ответ на который будет не настолько простым, ведь дальше мы будем говорить о машинном обучении.
Как смартфон распознает рукописный ввод?
Вступление к своему обзору Galaxy Note 10+ я написал от руки на том же аппарате при помощи S-Pen. Для тех, кто не читал обзор, напомню, как это выглядело:

И, что интересно, смартфон распознал весь этот текст практически безошибочно, хотя некоторые буквы я уже и сам разобрать не могу. Как же он это сделал?
Рукописный текст — это обыкновенная картинка, черные пиксели на белом фоне. И задача смартфона сводится к распознаванию картинок. Согласен, такое объяснение ясности не добавило, поэтому подойдем с другой стороны.
Для распознавания картинок используются нейросети. Если мы говорим о распознавании объектов на снимке (людей, животных, предметов), используются сверточные нейронные сети. Но текст можно распознавать и при помощи самых простых нейросетей под названием перцептрон (правда, точность такого распознавания будет на порядок ниже, чем если бы этим занялась сверточная нейросеть).
Давайте для удобства сведем всю задачу к распознаванию одной цифры. То есть, вначале смартфон разбивает весь текст на отдельные маленькие картинки, каждая из которых содержит один единственный символ. К примеру, в квадратике 28×28 пикселей оказалась цифра 9 (почерк максимально неразборчивый):

Ну это мы понимаем, что перед нами цифра 9, а для смартфона — это набор пикселей различной яркости. Так как размеры рисунка составляют 28 на 28 пикселей, такая картинка содержит всего 784 пикселя (28×28). Если мы разложим ее на отдельные пиксели, получим примерно следующее:
Пиксели здесь показаны в виде кружочков. Мы видим, что большая их часть не закрашена совсем, некоторые пиксели — полностью черные, другие — слегка серые. Яркость каждого пикселя записана числом от 0 до 255, где 0 — отсутствие света (полностью черный пиксель), а 255 — максимальная яркость (пиксель белый). Но давайте для нашего примера будем считать наоборот, 0 — ничего нет (пиксель белый), а 255 — черная точка, то есть, в таком пикселе больше всего черного цвета. Так будет удобнее понимать, а на суть это никак не влияет.
Теперь возьмем все эти пиксели и выстроим их в один длинный ряд (вначале идут первые 28 пикселей, затем берем 28 пикселей со второй строки, затем 28 — с третьей и так далее). У нас получится строка длинной в 784 пикселя.
Но если вы помните, в нейросеть нельзя подавать ничего, кроме чисел, так как это просто математическая модель, а не какой-то мифический искусственный разум. То есть, нам нужно перевести все пиксели в цифры.
Как я уже сказал чуть выше, цвет пикселя задается определенным числом. В нашем случае, 0 — это отсутствие цвета, то есть, в этой точке нет никакого текста, а 255 — это максимально черная точка, там явно есть рукописный текст. Соответственно, чем ближе число к нулю, тем светлее точка. Вот мы и перевели длинный набор пикселей (графическую информацию) в длинный ряд чисел:
0 0 0 0 0 0 0 0 0 0 50 60 90 130 250 255 200 30 20 0 0 0 0 0 100 130 0 0 …
Именно так и видит нашу цифру «9» смартфон. Это просто последовательность из 784 чисел (для картинки 28 на 28 пикселей). Но как в этом наборе чисел распознать девятку, написанную от руки?
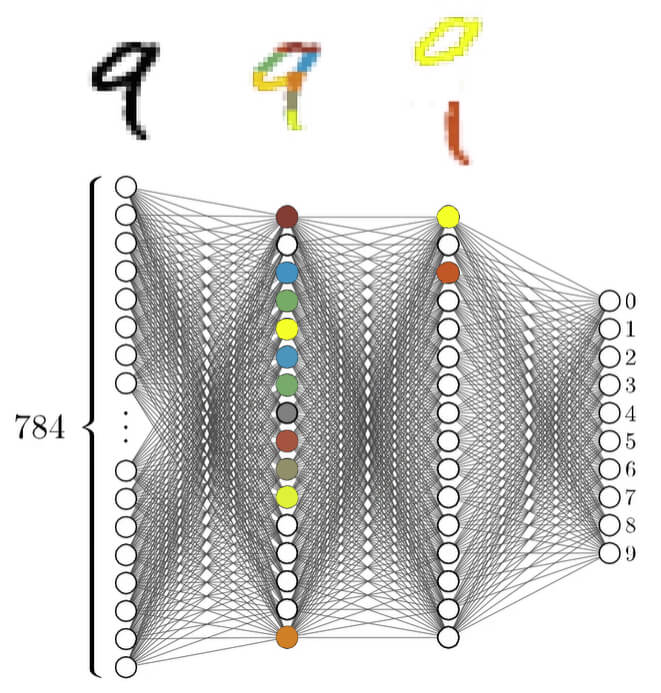
Для этого нужно передать все полученные числа в нейросеть. То есть, у нас будет 784 нейрона в первом слое и в каждый нейрон мы записываем число, соответствующее одному из пикселей. Если вы не понимаете, что такое нейроны, откуда они взялись и как туда что-то записать, повторюсь, почитайте первую часть статьи.
Вот схема нашей нейросети, которая будет распознавать цифры, записанные от руки:
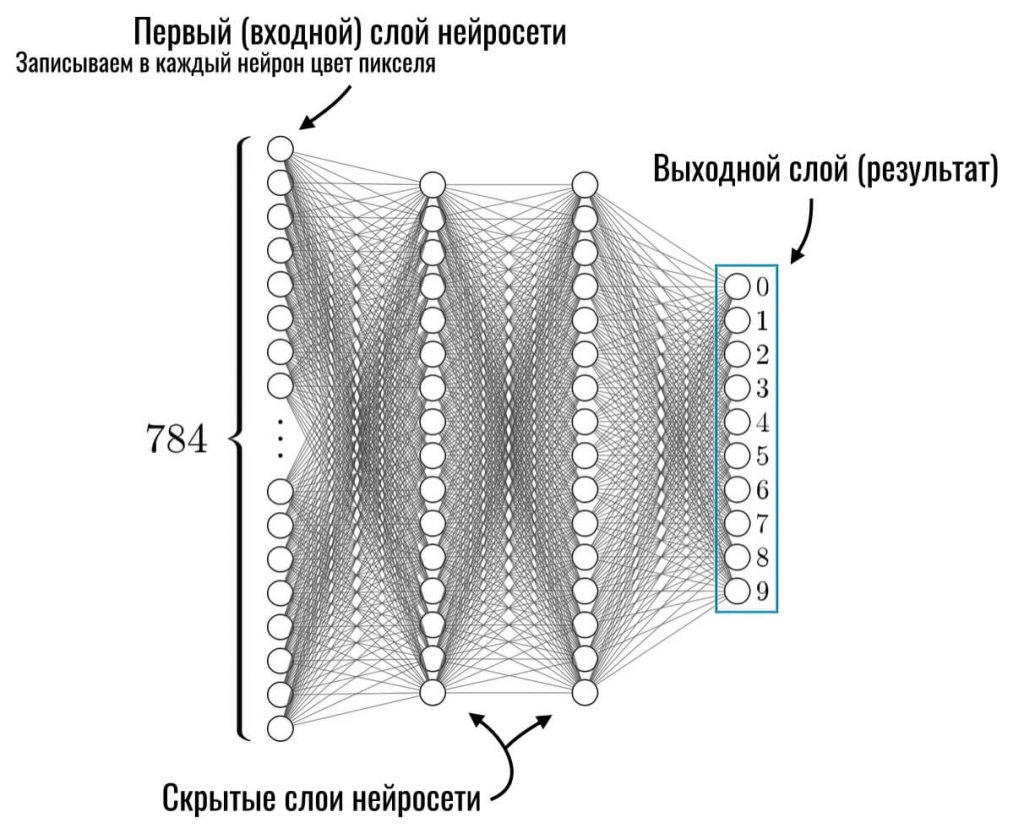
Если вы немножко запутались — это нормально. Сейчас всё станет понятнее. На входе в нейросеть мы подаем 784 числа — в каждый нейрон по одному числу, соответствующему яркости конкретной точки. Каждый нейрон первого слоя связан со всеми нейронами второго слоя и так далее. Это же сеть, в конце концов.
Все нейроны первого слоя передают свои числа во второй слой, но проходя по каждой конкретной связи, эти числа умножаются на определенный вес. Например, если первый нейрон первого слоя отправляет свои данные в первый нейрон второго слоя, его число умножается на 0, то есть, обнуляется. А если, к примеру, данные отправляются в десятый нейрон второго слоя, его число умножается на 2, то есть, «сигнал» усиливается вдвое. Откуда мы взяли эти веса — пока не важно. Просто нужно понимать, что так работает нейросеть (я подробно рассказывал об этом в первой части).
Далее нейроны второго слоя передают свои числа в третий слой и эти числа снова умножаются на веса. В итоге, в третьем слое активируются всего несколько нейронов, так как значения остальных нейронов близки к нулю.
Теперь оставшиеся нейроны третьего слоя передают свои числа в последний слой и мы видим, что здесь уже активируется лишь один нейрон, соответствующий цифре, которую наша нейросеть распознала:
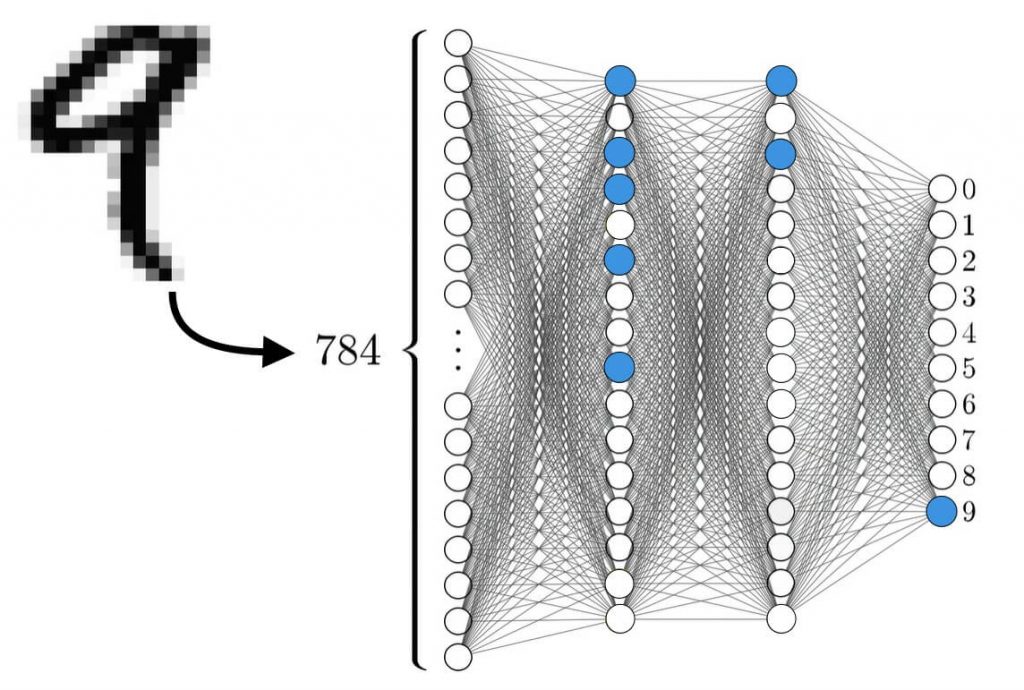
Как же такое могло произойти? Почему именно эти нейроны активировались при прохождении по ним простых чисел?
Давайте пойдем с конца и подумаем, почему активировался нейрон, соответствующий цифре 9 на выходе? По сути, рукописная девятка из нашего примера — это цифра, состоящая из кружочка сверху и палочки справа:
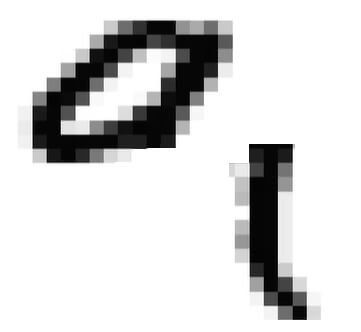
Можно предположить, что первый нейрон в предпоследнем слое ассоциируется с кружочком. То есть, если на картинке будет что-либо похожее на кружочек, рано или поздно активируется этот нейрон. Помните, в каждом нейроне суммируются все сигналы, пришедшие с предыдущих. Соответственно, если активировался этот нейрон, значит, сюда поступило много пикселей (чисел), относящихся к форме круга. То же касается и палочки, то есть, третьего нейрона предпоследнего слоя.
Если бы мы взяли только этот слой и посмотрели, кому он отправил свой сигнал (определенное число), то получили бы следующую картину:
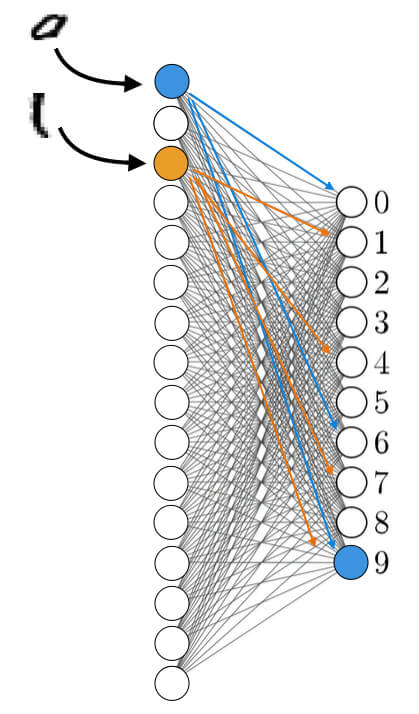
Как видим, первый нейрон (ассоциирующийся с кружочком) может соответствовать таким числам: 0, 6, 8 и 9. В каждом из них мы видим очертания круга.
Наш первый нейрон как раз и передал определенное число этим нейронам (синие связи на картинке). Если бы больше никакие нейроны ничего не передавали, смартфон определил бы цифру 0, так как связь этого нейрона с нейроном, соответствующим нулю — самая сильная. То есть, число умножается на самый большой вес.
Но затем мы видим, что активировался еще третий нейрон (отвечающий за вертикальную палочку) и он может соответствовать числам: 1, 4, 7 и 9 (оранжевые связи на картинке). Получается, в 9-й нейрон поступили сигналы с двух других нейронов, а их числа суммировались. Поэтому число в этом нейроне самое большое (больше, чем в первом, соответствующем нулю). Теперь смартфон с высокой вероятность распознает в нашем символе именно число 9.
Но почему в третьем слое активировались два нейрона, соответствующих кружочку и палочке?
На самом деле, кружок ведь тоже состоит из определенных фигур/частей:

Значит, в предыдущем слое нейроны, соответствующие этим примитивным формам (короткая горизонтальная палочка, полукруглая палочка, расположенная по диагонали и т.д.), так передавали свой вес, что самые большие числа оказались именно в этих двух нейронах, отвечающих за кружочек и вертикальную палочку.
Но остается вопрос — каким образом получились эти примитивные формы во втором слое, если на первом слое каждый нейрон соответствует лишь определенному пикселю. Почему эти отдельные пиксели сложились в такие примитивные формы?
Давайте предположим, что мы вручную решили настроить веса всех связей так, чтобы первый нейрон второго слоя активировался только, если в центральной части распознаваемой картинки есть горизонтальная палочка (как в цифре семь). Сделать это очень легко, мы ведь знаем, где находится центр картинки по пикселям (скажем, от 370-го до 400-го пикселя). Эти пиксели будут иметь самые сильные связи с первым нейроном второго слоя.
Получается, если пиксели 370-400 будут закрашены, соответствующие нейроны первого слоя активируют первый нейрон второго слоя, а дальше по цепочке активируются следующие слои вплоть до нейрона, соответствующего цифре 9 в последнем слое.
Остается последний вопрос — кто же настраивает все связи между нейронами, проставляя нужные веса всем связям? Другими словами, кто этот учитель, обучающий нейронную сеть распознавать цифры?
На самом деле, учителя нет. Нейронная сеть обучается самостоятельно. Все, что требуется от «учителя» — это дать нейросети огромное количество всевозможных вариантов написания цифр от руки и правильные ответы. Для этого существуют специальные базы данных. Например, в базе MNIST содержится 60 тысяч рукописных цифр в виде маленьких картинок 28 на 28 пикселей. Эта база и загружается в нейросеть для обучения.
Сам процесс обучения — это тема для отдельного разговора. Но важно понимать следующее — все происходит автоматически. Изначально нейросеть выдает случайный результат, так как все веса связей не настроены. Затем нейросеть определяет ошибку (мы же предоставили ей верный ответ). Используя определенные математические формулы, все связи с предыдущим слоем корректируются. То есть, из веса каждой связи вычитается погрешность. Затем распространение этой корректировки идет к следующим слоям, пока не дойдет до первого слоя. Этот процесс называется обратным распространением ошибки.
После нескольких тысяч таких проходов все веса настраиваются более-менее корректно. Затем обученную нейросеть загружают в смартфон, чтобы она распознавала рукописный ввод.
Вот так немножко запутанно, но интересно работает искусственный интеллект.
Алексей, главный редактор Deep-Review (alexeysalo@gmail.com)
При подготовке некоторых иллюстраций к этой статье были использованы материалы 3blue1brown
P.S. Не забудьте подписаться в Telegram на наш научно-популярный сайт о мобильных технологиях, чтобы не пропустить самое интересное!